
Built during the Hacking Bridge hackathon, COR PETIT measures how hospitalized children feel before and after each play session by combining facial expression recognition and natural language analysis. A friendly mascot guides the conversation while two AI models (FER + MTCNN for video and a 28-emotion NLP classifier for speech) generate real-time, objective reports for clinicians, without storing any images or video. The result is a non-invasive, GDPR and EU AI Act-compliant tool that lets specialists see emotional change instead of guessing it.
Pediatric specialists rely on what kids can put into words, but young patients in pain, fatigue, or fear often can’t. COR PETIT closes that gap by reading the signals their face and voice already give off, adding an objective layer of insight without another invasive test.
Context
Young patients in hospital settings frequently struggle to verbalize their emotional state. Traditional assessment tools rely on subjective self-reporting, which is especially limited for children under stress. Clinicians are left to interpret behavior with incomplete information.
Approach
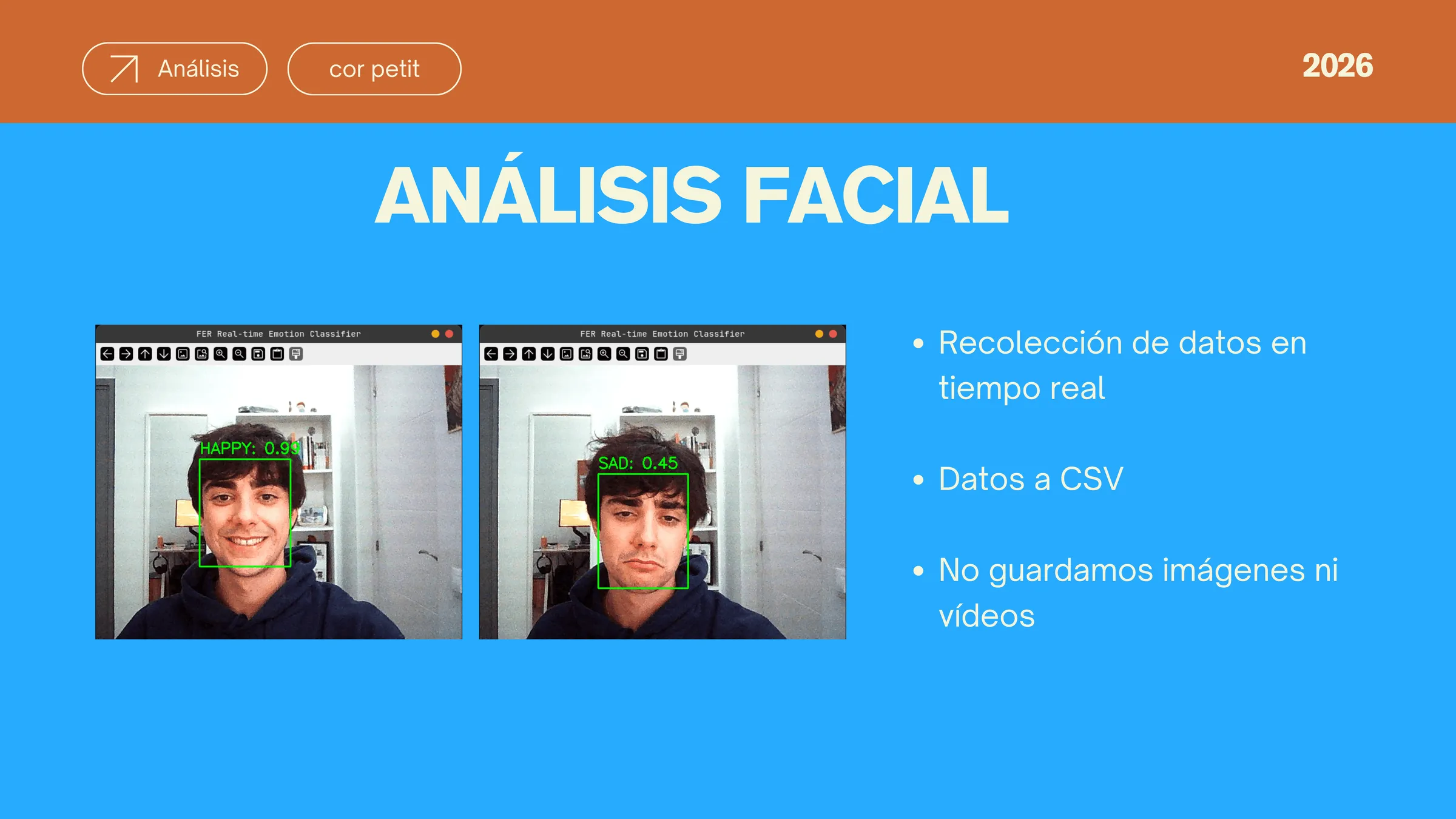
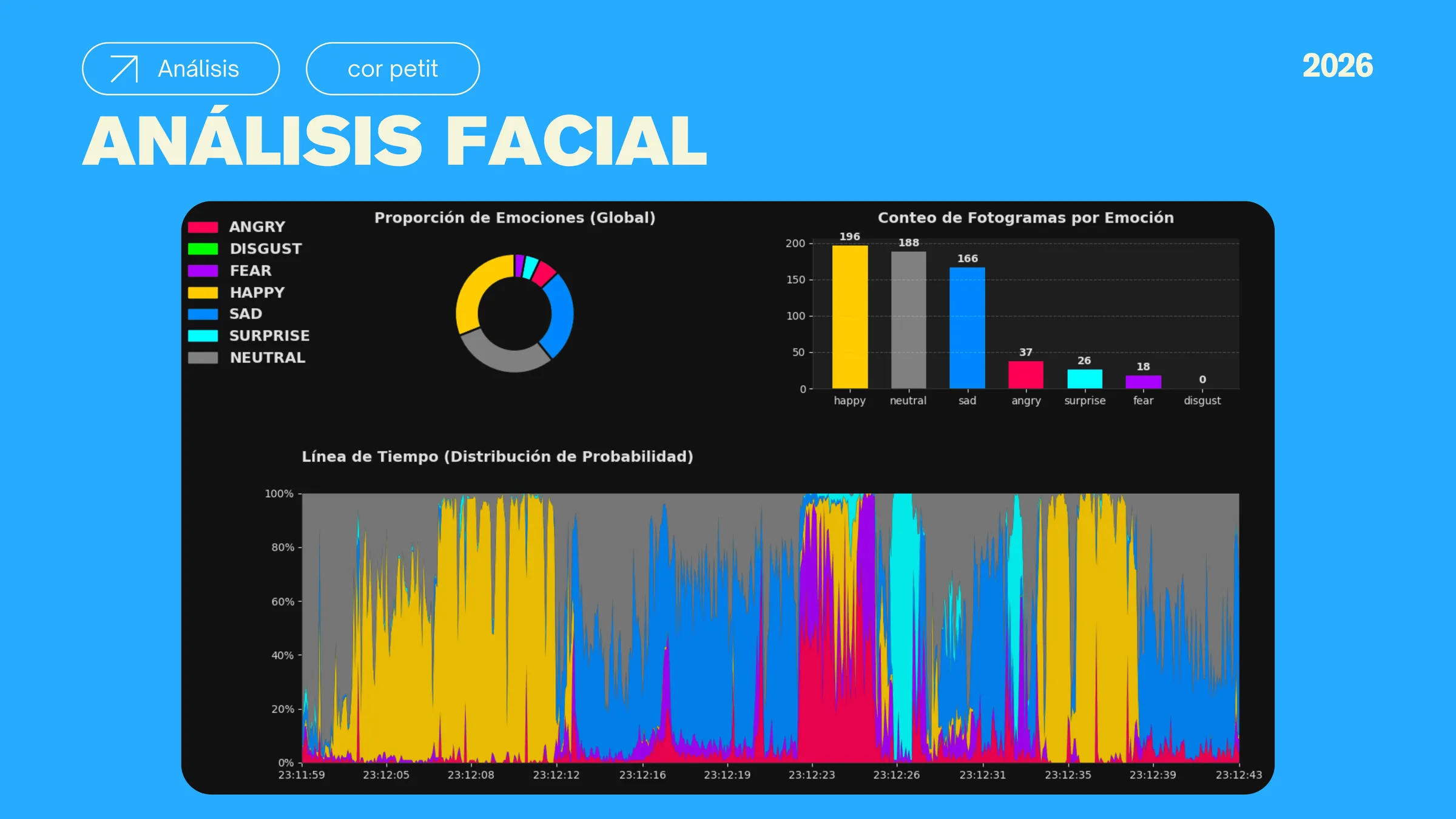
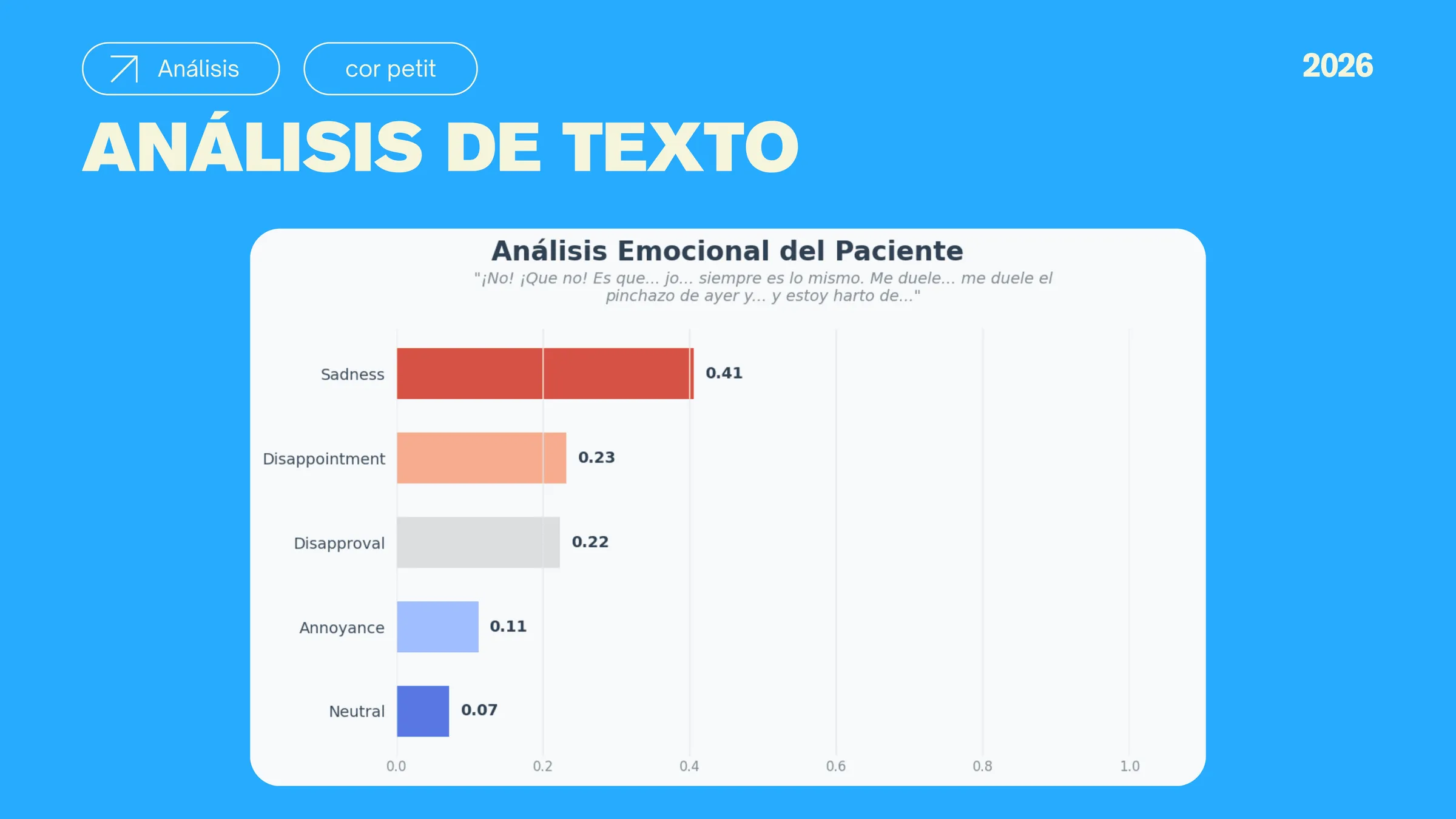
Two complementary AI models work in parallel: a computer vision pipeline using FER and MTCNN to analyze facial micro-expressions in real-time video frames, and a 28-class NLP emotion classifier that processes transcribed speech. Neither model stores raw video; only aggregated scores pass to the reporting layer.
Privacy by design
Full GDPR and EU AI Act compliance was non-negotiable. Every architectural decision starts from the question: what is the minimum data needed to be useful? The answer shapes what gets processed, what gets discarded, and what clinicians actually see.
My role
I led the product design and integrated the engineering into a single coherent product, owning all visual and interaction design and co-leading the pitch that won the round.
Impact
The team won Best Pitch at the Hacking Bridge hackathon and delivered the working solution to Talentum Gaudium, the foundation that brought the original problem. The full solution was handed off to Talentum Gaudium for them to take forward.









— Video
DEMO VIDEO
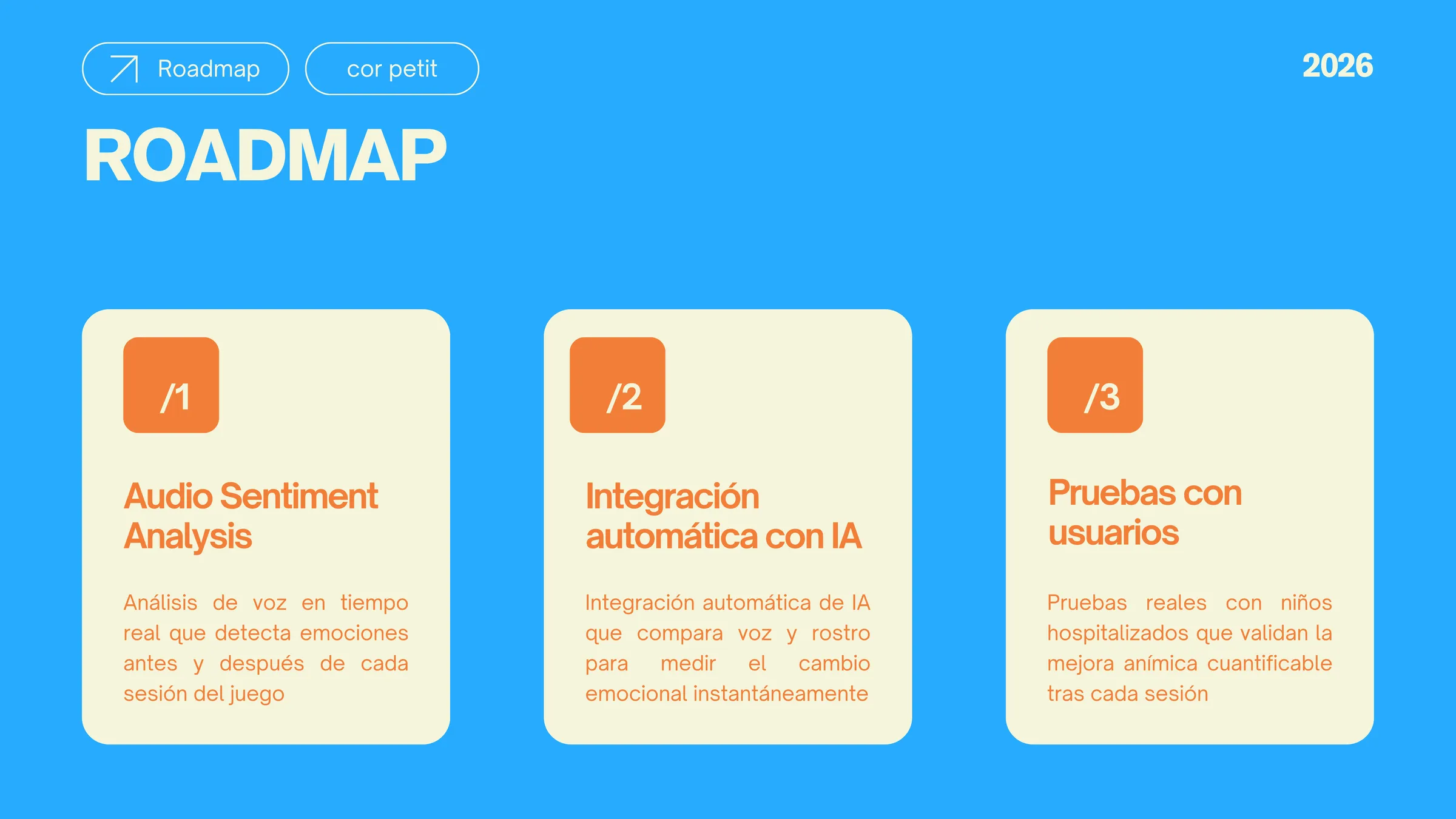
Beyond the prototype, the roadmap moves toward real-time audio sentiment analysis, full cross-modal AI integration, and validation trials in pediatric wards. The principle stays simple: their voice and gaze never lie. We just need to learn to listen.